

해당 글은 “이것이 취업을 위한 컴퓨터 과학이다.” 를 읽고 요약한 글 입니다.
자세한 내용은 책을 참고하시길 바랍니다.
드디어 마지막인 이번 글에서 요약할 내용은 효율적 쿼리, 데이터베이스 설계, NoSQL에 대해서 정리해보겠습니다.
4. 효율적 쿼리
서브 쿼리와 조인
서브 쿼리(subquery)는 다른 SQL문이 포함된 SQL문을 의미하며, 조인(join)은 2개의 테이블을 하나로 합치는 것을 의미합니다.
이들은 여러 테이블에 질의하는 등 데이터베이스에 복잡한 요청을 해야 할 때 유용하게 사용될 수 있습니다.
MySQL의 공식 문서에서는 서브 쿼리를 다른 SQL문 안에 있는 SELECT문으로 정의합니다.
이러한 서브 쿼리는 소괄호로 감싸 외부 쿼리와 구분한다고 합니다.
서브 쿼리의 다양한 유형이 있지만 다음의 대표적인 2가지 유형이 있습니다.
- SELECT 문 안에 SELECT 문이 포함된 서브 쿼리
- DELETE 문 안에 SELECT 문이 포함된 서브 쿼리
조인의 경우에도 다양한 종류가 있으며, 대표적인 조인은 크게 INNER 조인과 OUTER 조인으로 나눌 수 있습니다.
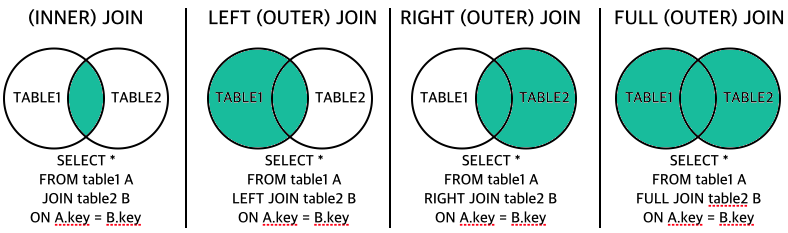
- INNER 조인 : 테이블 1과 2의 레코드 중 조인 조건을 모두 만족하는 레코드를 결과로 반환함
- OUTER 조인
- LEFT OUTER 조인
- 테이블 1의 모든 레코드 + 조인 조건을 만족하는 테이블 2의 레코드를 결과로 반환
- 조건을 만족하지 않는 테이블 2의 필드는 NULL
- RIGHT OUTER 조인
- 테이블 2의 모든 레코드 + 조인 조건을 만족하는 테이블 1의 레코드를 결과로 반환
- 조건을 만족하지 않는 테이블 1의 필드는 NULL
- FULL OUTER 조인
- 테이블 1과 2의 모든 레코드를 결과로 반환
- 조건을 만족하지 않는 경우에 상대 테이블의 필드를 NULL로 채워 반환
- MySQL을 포함한 많은 RDBMS에서는 FULL OUTER 조인 문법을 명시적으로 지정하지 않음 → UNION 사용
- LEFT OUTER 조인
- UNION : SQL문 실행 결과의 합집합을 구하는 키워드
뷰
뷰(view)는 SELECT문의 결과로 만들어진 가상의 테이블입니다.
SELECT문의 결과를 뷰로 생성한 뒤, 해당 뷰에 다양한 SQL문을 실행해 볼 수 있습니다.
뷰는 쿼리의 단순화, 재사용성을 높이기 위해 많이 사용됩니다.
여러 테이블을 조인하거나 복잡한 조건식을 사용한 SQL문을 하나의 뷰로 만들어두면, 이후 복잡한 SQL문을 반복적으로 작성하는 대신 단순하게 동일한 결과를 얻을 수 있습니다.
또, SQL문을 단순화하기 위해 사용하기도 하고, 특정 사용자에게 테이블의 특정 데이터만을 보여주고자 할 때도 사용할 수 있습니다.
이러한 뷰를 사용할 때 유의할 점은 조회에는 제한이 없지만 이 외(추가, 삭제 등)는 불가능할 수도 있습니다.
그래서 주로 조회를 목적으로 사용되는 경우가 많습니다.
인덱스
RDBMS의 성능을 향상시키는 대중적인 방법인 인덱스(index)는 검색 속도 향상을 목적으로 만드는 하나 이상의 테이블 필드에 대한 자료구조입니다.
특정 필드에 대한 인덱스를 생성하면 인덱스를 기준으로 원하는 레코드에 더 빠르게 접근할 수 있습니다.
인덱스의 종류는 크게 2가지로 구분됩니다.
- 클러스터형 인덱스 (clustered index)
- 테이블당 하나씩 만들 수 있는 인덱스
- 대표적으로 테이블 내에 기본 키로 지정된 필드가 있음
- 기본 키로 지정된 필드가 없는 경우에는 NOT NULL 제약 조건과 UNIQUE 제약 조건이 있는 필드를 클러스터형 인덱스로 간주함
- 세컨더리 인덱스 (secondary index)
- 논클러스터형 인덱스라고도 부름
- 테이블당 여러 개가 존재할 수 있지만 상대적으로 느림
이러한 인덱스는 언제 활용해야 하는 걸가요?
인덱스가 성능을 높일 수 있는 조회(SELECT) 연산이 적은 경우나 삽입(INSERT), 수정(UPDATE), 삭제(DELETE) 연산이 많은 경우에는 굳이 인덱스가 필요하지 않습니다.
삽입하거나 수정/삭제할 때 인덱스에 대한 작업도 동시에 이루어져야 하기 때문에 오히려 성능을 떨어뜨릴 수 있기도 합니다.
또, 테이블당 인덱스의 개수가 지나치게 많은 것도 지양해야 합니다.
일반적으로 테이블당 3개 이하의 인덱스를 권고합니다.
5. 데이터베이스 설계
ER 다이어그램 (ERD)
데이터베이스를 구성하는 요소들의 관계(엔티티 관계)를 나타내는 그림인 ER 다이어그램(이하 ERD)이 있습니다.
ERD는 데이터베이스에 저장되는 엔티티의 구조를 모델링하는 것을 목적으로 합니다.
ERD를 활용해 데이터베이스의 구조를 명확하게 정의해두면 추후에 데이터베이스를 확장하거나 수정할 때 어떤 부분이 영향을 받는지 쉽게 파악할 수 있습니다.
이를 통해 유지보수가 용이하고, 개발자 간 원활한 소통이 가능합니다.
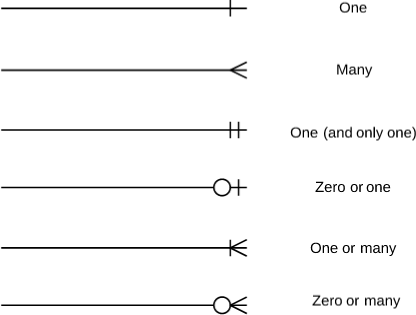
위와 같은 테이블 간의 관계를 나타내는 표기는 ERD에서 중요한 개념이므로 기억해두는 게 좋습니다.
정규화
정규화(Normal Form)란 잠재적인 문제가 발생하지 않도록 테이블의 필드를 구성하고, 필요할 경우 테이블을 나누는 작업입니다.
정규화된 테이블의 형태를 정규형이라 부르고, 영문 그대로 NF (Normal Form)이라고 부릅니다.
이러한 정규형의 종류는 다음과 같습니다.
- 제1 정규형
- 모든 속성이 원자 값을 가진다는 것
- 필드 데이터가 더 이상 쪼개질 수 없는 값을 가져야 한다는 것을 의미
- 제2 정규형
- 제1 정규형을 만족함과 동시에, 기본 키가 아닌 모든 필드들이 모든 기본 키에 완전히 종속될 것
- 기본 키가 여러 필드로 구성될 경우 일부 기본 키에만 종속 되어도 안 됨
- 제2 정규형은 부분 함수 종속성이 없는 상태며, 완전 함수 종속인 상태라고 할 수 있음
- 부분 함수 종속성 : 기본 키가 아닌 필드가 기본 키의 일부에 종속되어 있는 경우
- 완전 함수 종속성 : 기본 키 전체에 완전하게 종속되어 있는 경우
- 제3 정규형
- 제2 정규형을 만족하면서, 기본 키가 아닌 모든 필드가 기본 키에 이행적 종속성이 없는 상태
- 이행적 종속 관계(transitive) : (A → B) + (B → C) = (A → C)
- 기본 키가 아닌 나머지 모든 필드들이 간접적으로라도 종속되어서는 안 됨
- 보이스/코드 정규형 (Boyce-Codd Normal Form, 이하 BCNF)
- 제3 정규형을 만족하는 동시에 모든 결정자가 후보 키여야 함
- 결정자 : 특정 필드를 식별할 수 있는 필드를 의미
- 필드 A가 필드 B를 결정할 경우 A는 B의 결정자라고 할 수 있음
- 역정규화
- 정규화가 항상 최선인 것은 아님 → 참조하기 위한 성능상의 비용이 늘어날 수 있음
- 성능상의 이점을 최대한 활용하고자 할 때는 분할되어 있는 테이블을 하나로 합치는 작업을 함 (이것이 역정규화)
6. NoSQL
RDBMS vs NoSQL : NoSQL의 특징
NoSQL은 레코드를 테이블 형태 이외의 다양한 형태로 저장할 수 있고, SQL 이외의 방법으로 저장된 데이터도 다룰 수 있습니다.
대규모 데이터를 다루기에 용이하고 확장성이 좋아 최근 부상하고 있습니다.
높은 부하를 감당하거나 대용량 데이터를 다루는 분산 환경에서 빛을 발합니다.
대표적인 NoSQL 데이터베이스의 유형으로는 4가지가 있으며, 유형은 다음과 같습니다.
- 키-값 데이터베이스 (key-value database)
- 데이터베이스에 레코드를 키(필드)와 값의 쌍으로 저장하는 데이터베이스
- Redis, Memcached 등이 대표적
- 레코드를 보조기억장치가 아닌 메모리에 저장해 빠른 데이터베이스 접근 속도를 제공함
- 메모리에 저장되는 데이터베이스 → 인메모리 데이터베이스(in-memory database)
- 캐시나 세션 등 비교적 가벼운 정보를 저장하는 경우가 많음
- 주요 데이터베이스의 보조 데이터베이스로써 사용되는 경우도 많음
- 도큐먼트 데이터베이스 (document database)
- 레코드를 도큐먼트라는 단위로 저장하고 관리하는 데이터베이스
- 도큐먼트 : 정형화되어 있지 않은 NoSQL 레코드의 단위
- JSON, XML과 같은 형식을 도큐먼트로 활용함
- MongoDB가 대표적
- 하나의 레코드를 JSON 형태의 데이터로 만들어 관리함
- 고정된 스키마가 없기 때문에 각 도큐먼트가 유연한 스키마를 가질 수 있음
- 도큐먼트가 모이면 컬렉션, 컬렉션이 모이면 데이터베이스
- 레코드를 도큐먼트라는 단위로 저장하고 관리하는 데이터베이스
- 그래프 데이터베이스 (graph database)
- 데이터베이스에 저장하고자 하는 데이터를 그래프의 노드 형태로 저장하는 데이터베이스
- neo4j 등이 대표적
- SNS의 친구 관계나 교통망 같이 데이터 간의 관계성이 중요한 레코드를 저장하기 위해 주로 사용
- 칼럼 패밀리 데이터베이스 (column family database)
- Cassandra, HBase 가 대표적
- RDBMS와 같이 행(row), 열(column)이라는 개념이 있음
- 로우 키를 통해 특정 행을 식별
- 정규화나 조인을 사용하지 않고, 스키마가 고정되어 있지 않아 자유롭게 열을 추가할 수 있음
- 관련 있는 열들이 모여 칼럼 패밀리(column family), 칼럼 패밀리가 모여 키스페이스(keyspace)
마치며
느낀점
벌써 책을 마무리하게 되다니… 시간이 빠르게 흐르는 거 같습니다.
책을 요약하면서 그동안 부족했던 CS 지식을 채울 수 있는 계기가 되었습니다.
또, 책에서 쉽게 설명해주셔서 비전공자인 저도 어렵지 않게 이해가 쑥쑥 되었습니다.
Quiz
1. 뷰(view)에 대한 설명으로 올바르지 않은 것은?
A. 뷰는 가상의 테이블로, SELECT문의 결과를 저장한 것이다.
B. 뷰는 삽입, 삭제와 같은 조작이 자유롭다.
C. 복잡한 쿼리를 단순화하는 데 사용할 수 있다.
D. 특정 사용자에게만 테이블의 일부 데이터를 보여주는 데 사용할 수 있다.
2. 다음 중 제1 정규형(1NF)의 조건으로 올바른 것은?
A. 기본 키에 모든 필드가 완전하게 종속되어야 한다.
B. 모든 결정자가 후보 키여야 한다.
C. 모든 속성이 원자 값을 가져야 한다.
D. 기본 키에 이행적 종속이 없어야 한다.
3. NoSQL 데이터베이스의 주요 장점으로 올바른 것은?
A. 테이블 간의 강력한 관계성을 제공한다.
B. SQL 쿼리문을 반드시 사용해야 한다.
C. 대규모 데이터를 다루기 좋고 확장성이 좋다.
D. 데이터 정규화가 필수적이다.
정답
1번 : B. 뷰는 삽입, 삭제와 같은 조작이 자유롭다.
2번 : C. 모든 속성이 원자 값을 가져야 한다.
3번 : C. 대규모 데이터를 다루기 좋고 확장성이 좋다.